
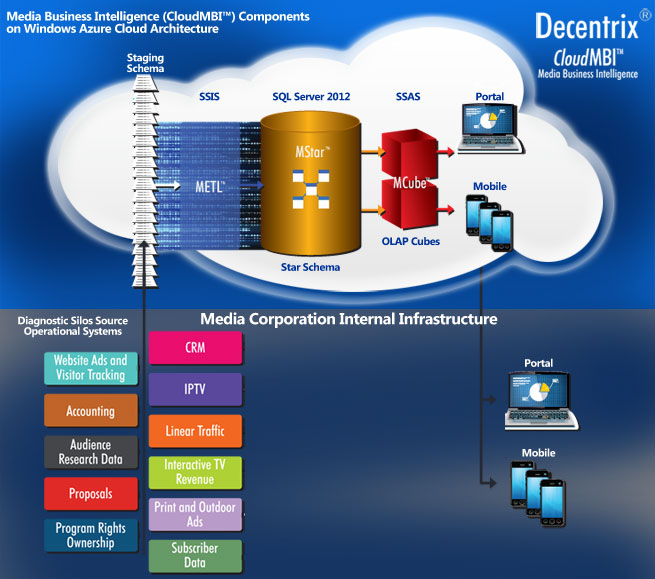
The components of the Media Business Intelligence cloud (CloudMBI™) supports five steps outlined in the BIAnalytix Architecture necessary to successfully execute a enterprise media data warehouse solution. Step 1, the extraction and ingestion of data from geographically dispersed source systems is easily accomplished. The required data formats - the staging schema - for ingestion are standardized so that new data sources only need a simple field-to-field mapping to this standard layout to be included in the next step of ETL ingestion to the data warehouse.
CloubMBI™ components
Extracter
Step 1, a source extractor moves the source system data into the Cloud Staging store. Each staging schema supports a class of source data (sales, traffic, accounting etc.). This staging store may be executed directly in the cloud, but normally is executed on a separate server resident in the Media organization's IT infrastructure, close to the source system. The choice is dependent on the sensitivity toward holding this level of granular data out of the cloud.
CloudMETL™
In step 2, the CloudMETL™ component is used to validate, cleanse, and transform the staging store data into the data warehouse's predefined star schema. This process normally will reside in the cloud architecture.
CloudMStar™
In Step 3, the cloud data warehouse repository, CloudMStar™, then accumulates the media dimension and fact records through the ETL process from each source system. The CloudMStar™ design is modular to allow each new source system to have its own repository within the single enterprise model. Once again this process normally will reside in the cloud architecture.
CloudMCube™
Step 4, the cloud OLAP cube, CloudMCube™ then provides the many millions of calculated totals for rapid access to media analysis. This also will reside in the cloud architecture in most instances.
CloudMPort™
The portal, CloudMPort™, for the presentation of dashboards and analysis reports may reside in the cloud, but may also be implemented in an existing portal architecture within the corporation.
Because Media corporations typically use systems from many different vendors across their businesses, each source system type requires an extraction process which normally executes at the end of each business day. This process extracts and maps the data from the source system and loads the data batch into the cloud staging schema. Some data sources permit changes to data that can be uploaded to the cloud on a near real time basis. In such cases, data can be processed through to the portal during the day.
Extractor systems normally execute within or near the source server and directly load the data, as a batch, up to the cloud staging schema. Because the staging schema is an open standard, the extractors are simple to implement and can be developed by the vendor of the source system, the client's IT department, or by Decentrix.
There are many classes of data that need to be included in an enterprise Media data warehouse system. Each class of data has a comprehensive staging schema or table defined for its ingestion. Each data class consists of many tables of dimensional data as well as one or more fact data tables. Each table defines all the attributes of that Media data object required for ingestion into the Media cloud. The full set of dimension and fact tables for each data class forms the content of a batch of data to be ingested from a source system. Note that multiple vendors will have different operational systems for each data class. The extractors for each vendor system will load a batch of data into the same staging data class schema; for example, all traffic vendors will load to the same staging data class.
There are a number of developed and tested extractors in the form of APIs available from operational system vendors. A number of operational systems today are also cloud based, generally web and new media, with extractors to move data from the operational system into the cloud staging stores. The process to map the extractions into the CloudMBI™ staging schemas is straightforward.
In the CloudMBI™ architecture, displayed in the diagram above, staging schemas are defined for many classes or sources of Media data. These classes often will be different for each segment of the Media industry (broadcast television, cable MSO, cable network, etc.).